更新
【release-1.0.7版本】2021年8月:资源优化了一个量级,文中单机3的测试,原来cpu 55,现在只用到5,是原来的1/10,内存只有480Mb,原来1G的一半。(主要原因,作者把topic暴力轮询改成匹配树,点赞!)
背景
早先是用老外的moquette(主要是因为要定制开发,还有我们主要用Java语言),实际开发碰到了一些问题,想换个综合比较好的框架,恰巧发现了smqtt,但是也得经过测试才能换呀,本文就是对测试结果做个介绍,方便想选smqtt的小伙伴。 碰到的问题可以参考:https://zhuanlan.zhihu.com/p/352861858 SMQTT地址:https://github.com/quickmsg/smqtt
摸石头过河
刚开始没摸着门路,瞎测试,碰到了不少问题,建议大家先根据自己的公司的当前业务与将来发展预期的业务,做个估算,先定个预期目标,再开始测试。
首先:我用Coolpy7_benchmark测试,但是一定要去看下他的测试代码,基本他的测试逻辑不会是你想要的(作者不要骂我哈,这个工具是相当好,我得提醒下其他小伙伴逻辑的一些问题),但是你可以改动它。
Coolpy7_benchmark地址:https://github.com/Coolpy7/coolpy7_benchmark
比如这里:
 假设你设置的链接1万个,就是
假设你设置的链接1万个,就是workers=1万,它会整1万个线程,每个线程给1万个链接发消息,那就是一下子有1亿消息,我设置了2.8万发布者和2.8万订阅者,打崩smqtt了(单机,cpu4核内存8G,达到cpu400%),确实是这个测试代码的问题,因为我还去测试了算比较稳定的emqx,也是把cpu打到400%,内存都还好。
这里可以看我修改后,[ps:为此我学了go的基础语法,基础不难,你也可以。]
地址:https://gitee.com/leafseelight/coolpy7_benchmark/tree/master/test_all_cus
 这边有代码也有编译好的文件,可以自己选,如果你跟我一样是首次接触go,编译自己写的代码没有响应,其实是仓库无法访问,运行:
这边有代码也有编译好的文件,可以自己选,如果你跟我一样是首次接触go,编译自己写的代码没有响应,其实是仓库无法访问,运行:go env -w GOPROXY=https://goproxy.cn即可,具体可以参考这篇文章:点这里
假定测试目标
假订一个场景,我们这个业务用在单车上,当前业务假定4000台设备,假定设备逐年翻倍增长。 第1年 4000 第2年 8000 第3年 1.6万 第4年 3.2万 第5年 6.4万 预先支撑个3-4年的发展就够了,就是说4万个,应该是足够。
那我们就假定有40000个设备,同一时间,设备通常只有1个人在操作,可以不考虑授权的用户,同样假定40000个用户。
这样子设备端就有40000个链接,订阅40000个topic,设备被操作一次,会反馈2条消息(运行中,成功),针对高峰期App端12000条/小时,这里应该是24000/条小时(400条/小时,6.6条/秒)
而APP高峰期假设1小时有25%的用户,就是10000个链接(bugly看的,高峰最高不超过25%,低的时候只有千分之五) 那App就是10000个链接,订阅10000个topic(设备的topic),部分用户可能重复操作,假设20%用户,消息就有12000条/小时,每秒3.3条。
综合:高峰期总链接数是,5万个,topic:4万个,消息是36000条/小时(600条/每分钟,10条/秒)
开始测试
因为我们准备做集群,而集群通过nginx的stream模块来统一提供地址和端口,也就是压力是可以平均分给集群下的机器,我们这边假定要集群部署2台,那单机只要测试上面目标的一半就够了。
另外,服务器(mqtt服务器端)参数调优,客户端(测试端)参数调优,参考cp7文档即可。文档地址:点这里
不过这里有个重要的东西,所有云服务都是禁用虚拟ip的,就是你设置了,实际不能生效。但是,你必须设置最少1个(代码可能有点问题),不然测试代码跑不起来。就是说云服务你也只能当做单机测试,最多支持发起6.4万左右的链接。这里还有一个要说明,公司电脑测试可能是行不通的,除非你公司的网络是千兆万兆网络,路由器工业级别,不然因为路由器是有链接数限制的,我们公司的我之前测试2千多个链接,结果所有人都上不了网了。汗!
单机测试
环境
3台阿里云服务器,其实2台就可以,这里走云服务器内网,可以忽略服务器带宽。 第1台,4核8G内存,装smqtt 第2台,4核8G内存,装cp7,执行设备端模拟 第3台,4核8G内存,装cp7,APP端模拟
单机1-模拟执行情况QOS为0
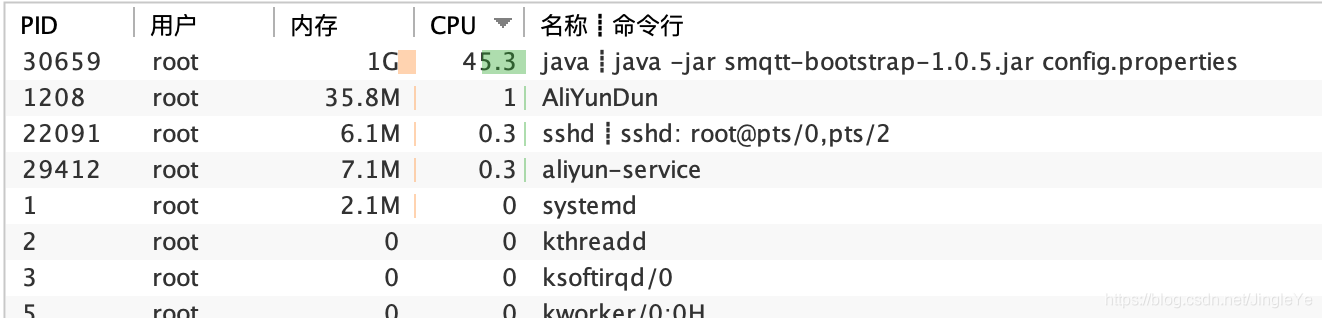
第2台,设备端模拟:2万链接,2万订阅者,2万topic,5千发布者,12000条/小时===>12000/5000=2.4条/小时,每个发布者2.4条/小时(算3条,就是20分钟一条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=20000 -receivers=20000 -publishers=5000 -cid=cccccccccccc -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1200000 -clear=true >run.log 2>&1 &
第3台,APP端模拟:5千链接,5千订阅,5千topic,5千发布者,6000条/小时===>6000/5000=1.2条每小时。每个发布者1.2条/小时(算2条,30分钟1条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=5000 -receivers=5000 -publishers=5000 -cid=app-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-aaaaaaaaa -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1800000 -clear=true >run.log 2>&1 &
未开始时,smqtt服务截图
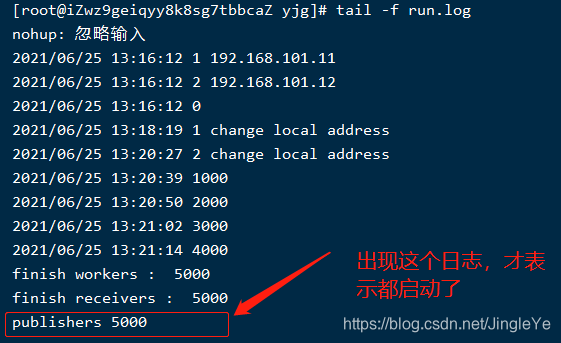
 顺便说一下,如果用我的代码测试,要仔细看最后那个日志出现了才表明完整启动。如图:
顺便说一下,如果用我的代码测试,要仔细看最后那个日志出现了才表明完整启动。如图:
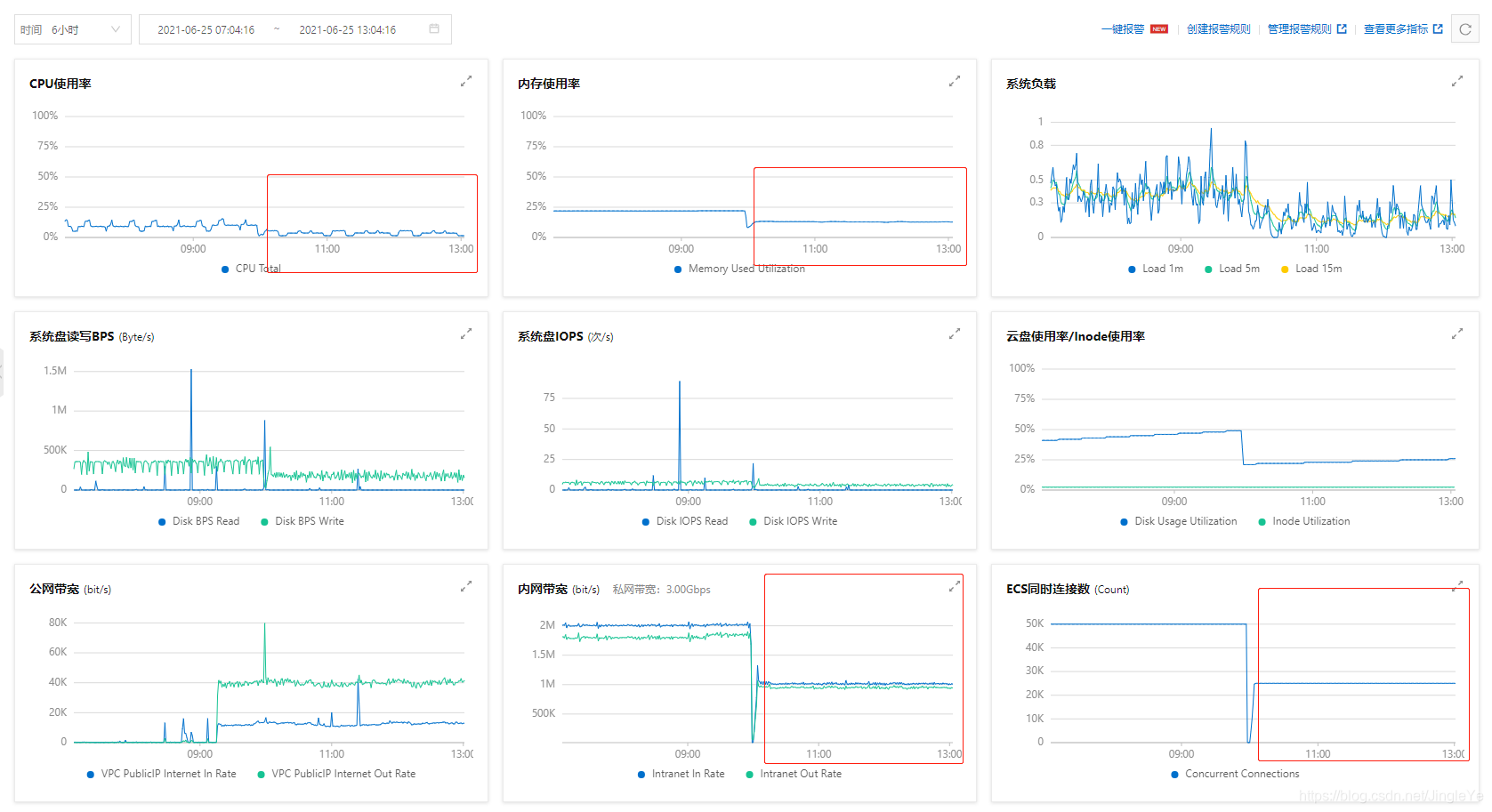
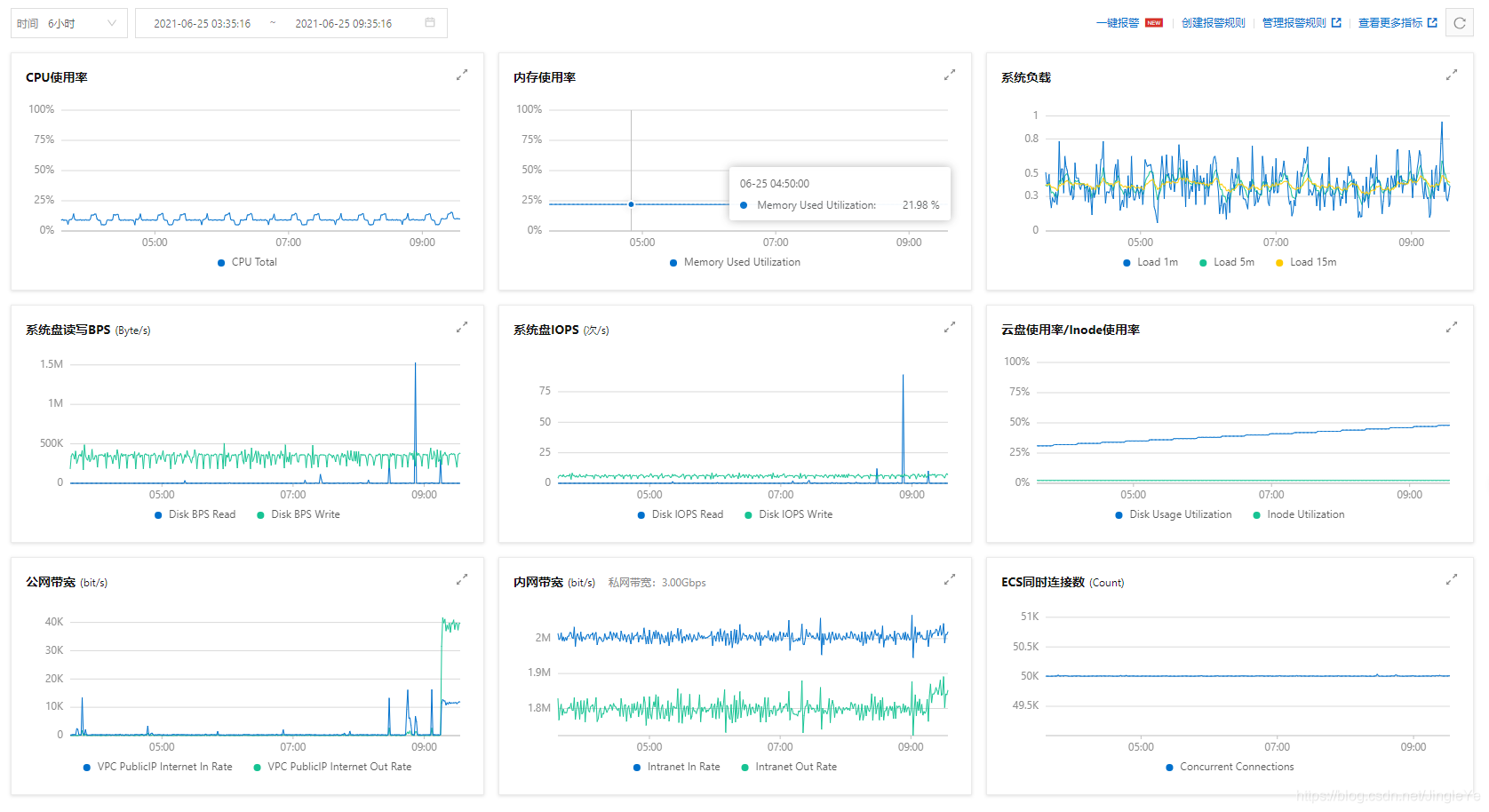
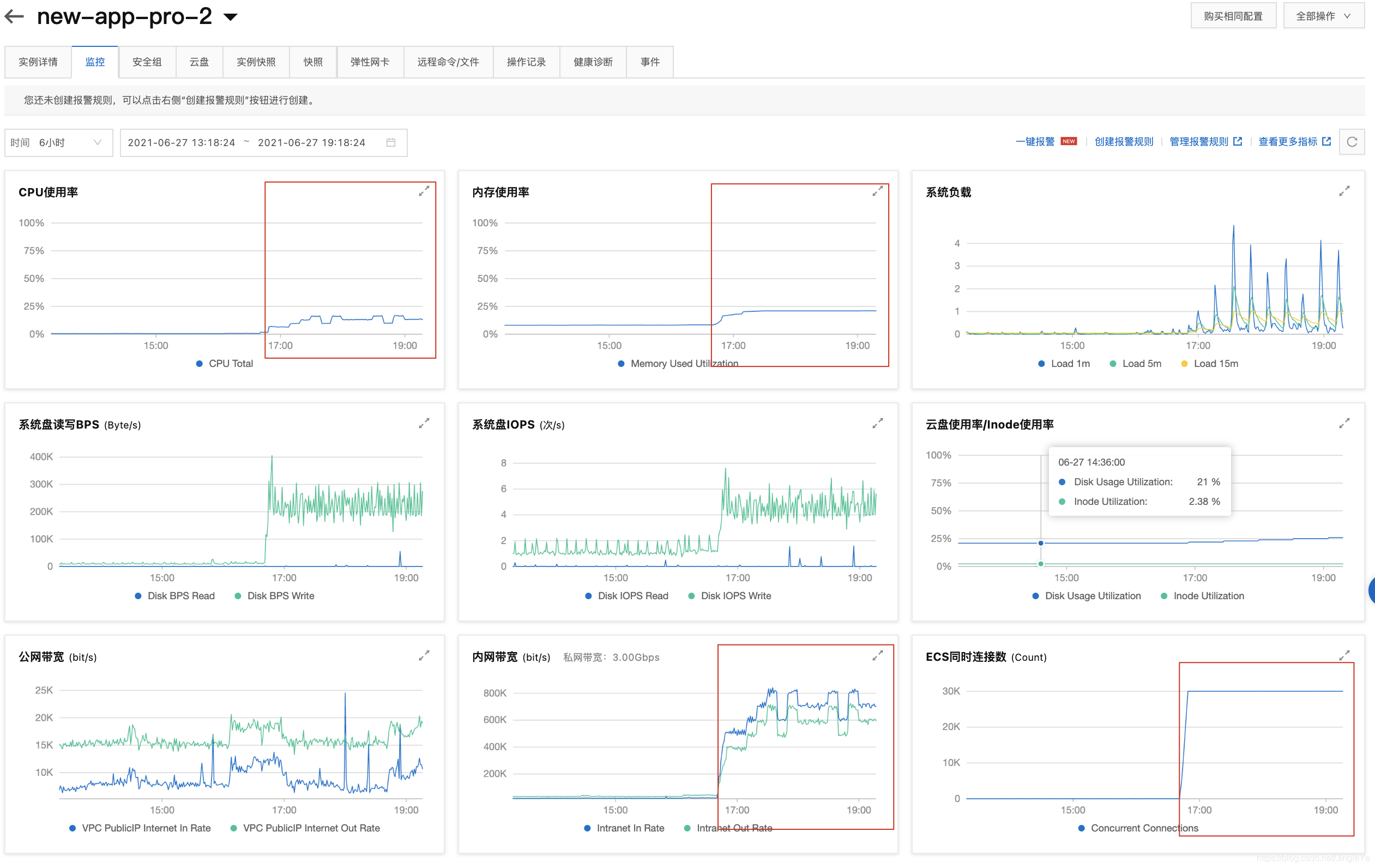
下面2张图是跑了2.5小时的监控图,可以看出来,还是非常稳定的。
 服务器Finallshell看
服务器Finallshell看

照比例看,4核8G,最高400%,400/20*2.5万,不说50万,因为还要考虑,消息集中某个时间点的量很大,20-30万,应该是还可以,这个是大致预估。
单机2-再模拟QOS1
更改后的测试代码 设备端:
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=20000 -receivers=20000 -publishers=5000 -cid=cccccccccccc -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=1 -keepalive=120s -s=44 -I=1200000 -clear=true >run.log 2>&1 &
App端:
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=5000 -receivers=5000 -publishers=5000 -cid=app-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-aaaaaaaaa -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=1 -keepalive=120s -s=44 -I=1800000 -clear=true >run.log 2>&1 &
运行将近2个小时的情况入下图:
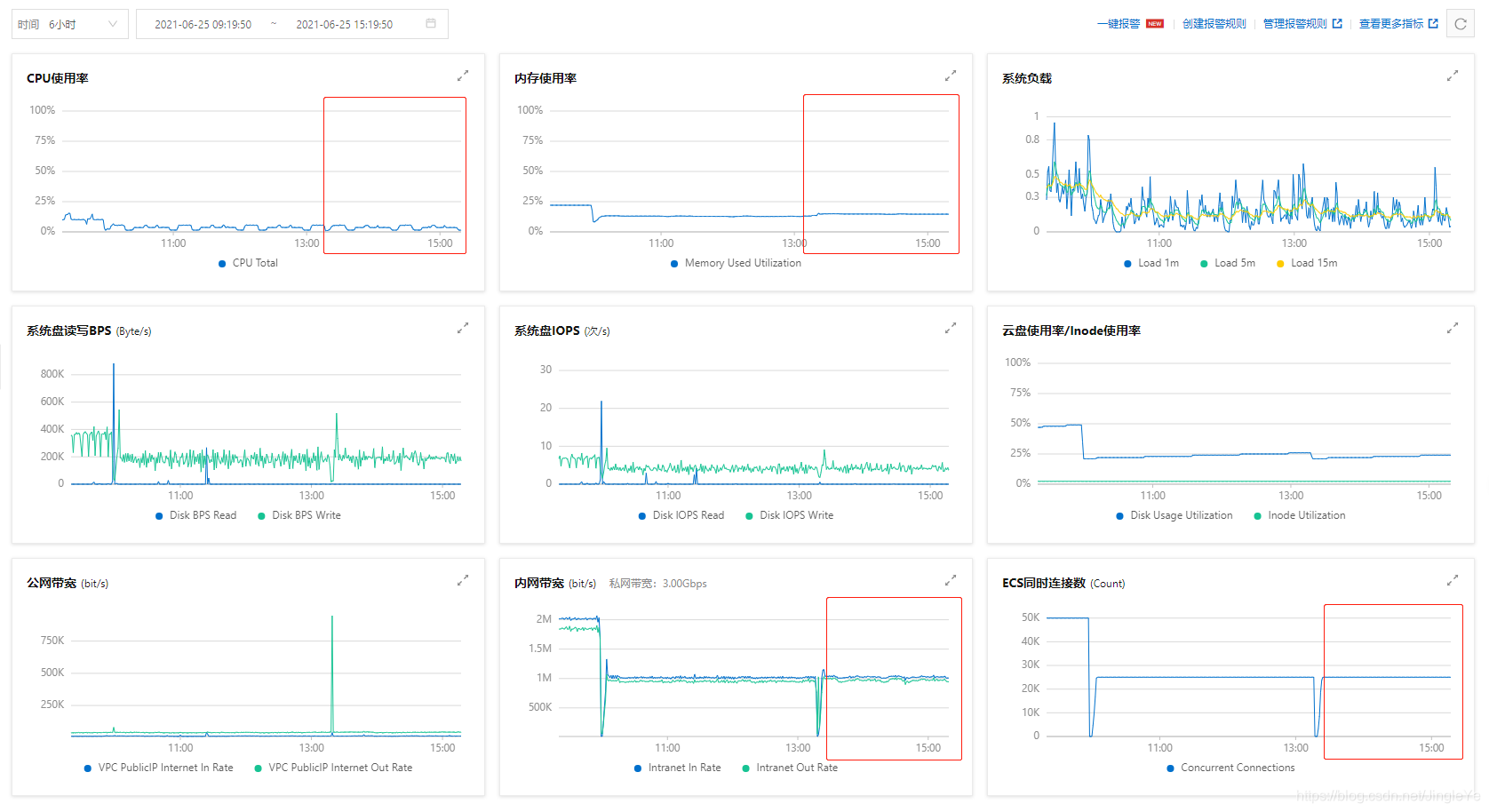 再看Finashell,如图:
再看Finashell,如图:
cpu11%-18%之间缓慢变化,从表现看很稳定。
单机3-单机翻倍测试(模拟集群只剩一台杠压力)
设备端模拟:4万链接,4万订阅者,4万topic,1万发布者,(app操作的2倍)24000条/小时===>每个发布者2.4条/小时(算3条,就是20分钟一条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=40000 -receivers=40000 -publishers=10000 -cid=cccccccccccc -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1200000 -clear=true >run.log 2>&1 &
APP端模拟:1万链接,1万订阅,1万topic,1万发布者,(假设1/5的用户多按了1次)12000条/小时===>每个发布者1.2条/小时(算2条,30分钟1条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=10000 -receivers=10000 -publishers=10000 -cid=app-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-aaaaaaaaa -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1800000 -clear=true >run.log 2>&1 &
合计:5万链接,5万订阅者,4万topic,2万发布者,消息中转处理,36000条/小时=600条/分钟,平均每个发布者1.8条/每小时(就是说4万设备,4万用户,高峰期25%的1万用户,一个小时内这些用户都去一次单车的量。)
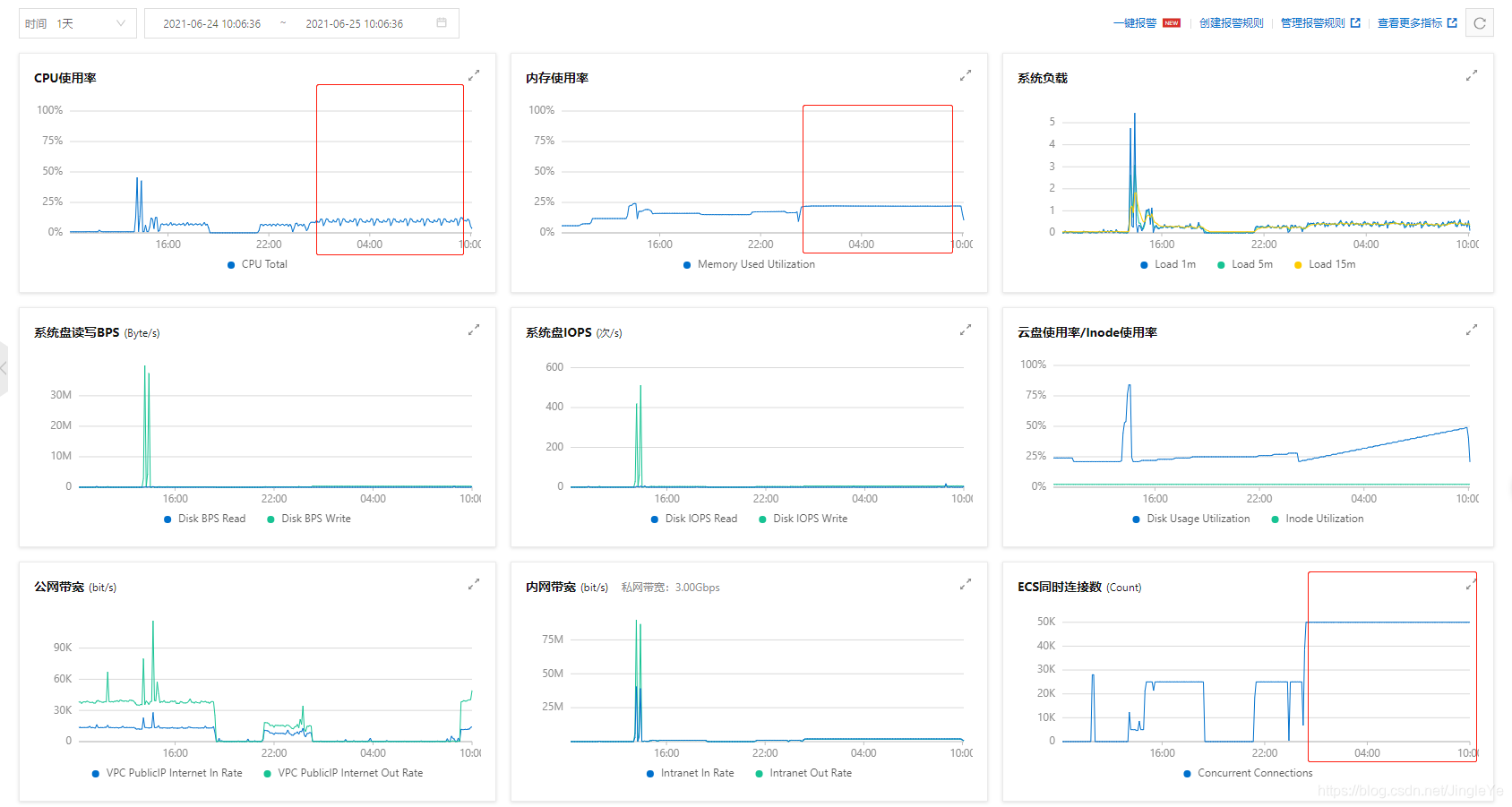
运行了9个多小时的情况截图:
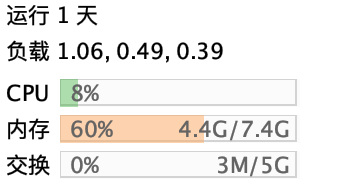
 按1天再截图一个:
按1天再截图一个:
我们再看看Finalshell

 依然非常稳定。
依然非常稳定。
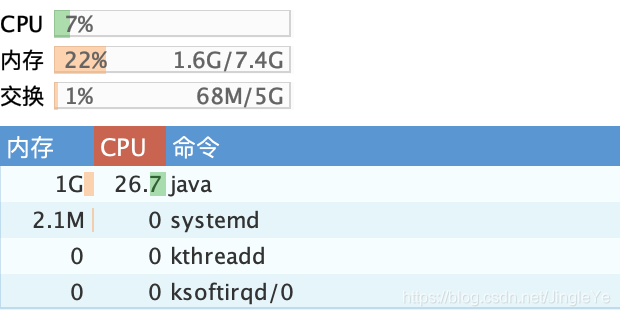
cpu在后台观察,是20%-55%之间缓慢变化,内存稳定在1G。由于消息我按20分钟去平铺,总是不能够完全平铺均匀,所以cpu会变化,另外内存方面,作者说用了PooledByteBuf,性能非常高,可以参考:https://blog.csdn.net/zero__007/article/details/73294783
【release-1.0.7版本】执行当前测试用例
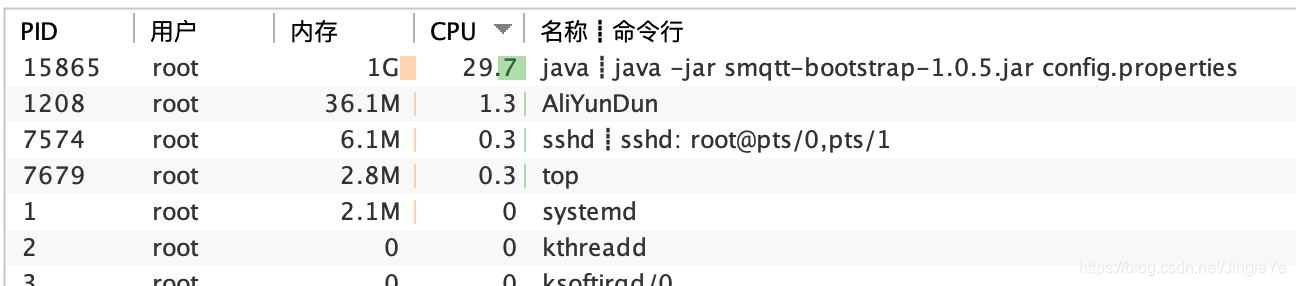
2021-08,作者把topic暴力轮询的设计,优化为匹配树方案。下图可以看到,cpu总共4核只占5%不到,内存只占465M,跟上面1.0.6版本对比,cpu只有1/10,内存只有1/2。一个量级的优化,点赞!
运行7天,截图如下:
可以看到:1.0.7 cpu非常低,不到2%;而1.0.6的时候cpu在5%-20%之间抖动。 Ps:忽略包名1.0.6,我没改。
集群测试
环境
第1台,4核cpu8G内存8M带宽,部署nginx与smqtt服务A
第2台,4核cpu8G内存5M带宽,部署smqtt服务B
其它2台,部署cp7执行测试
nginx的stream配置smqtt,weight都为1
集群1-打开全部压力
设备端模拟:4万链接,4万订阅者,4万topic,1万发布者,(app操作的2倍)24000条/小时===>每个发布者2.4条/小时(算3条,就是20分钟一条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=40000 -receivers=40000 -publishers=10000 -cid=cccccccccccc -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1200000 -clear=true >run.log 2>&1 &
APP端模拟:1万链接,1万订阅,1万topic,1万发布者,(假设1/5的用户多按了1次)12000条/小时===>每个发布者1.2条/小时(算2条,30分钟1条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=10000 -receivers=10000 -publishers=10000 -cid=app-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-aaaaaaaaa -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1800000 -clear=true >run.log 2>&1 &
合计:5万链接,5万订阅者,4万topic,2万发布者,消息中转处理,36000条/小时=600条/分钟,平均每个发布者1.8条/每小时(就是说高峰期,25%的人,每个人一个小时去开1次锁。)
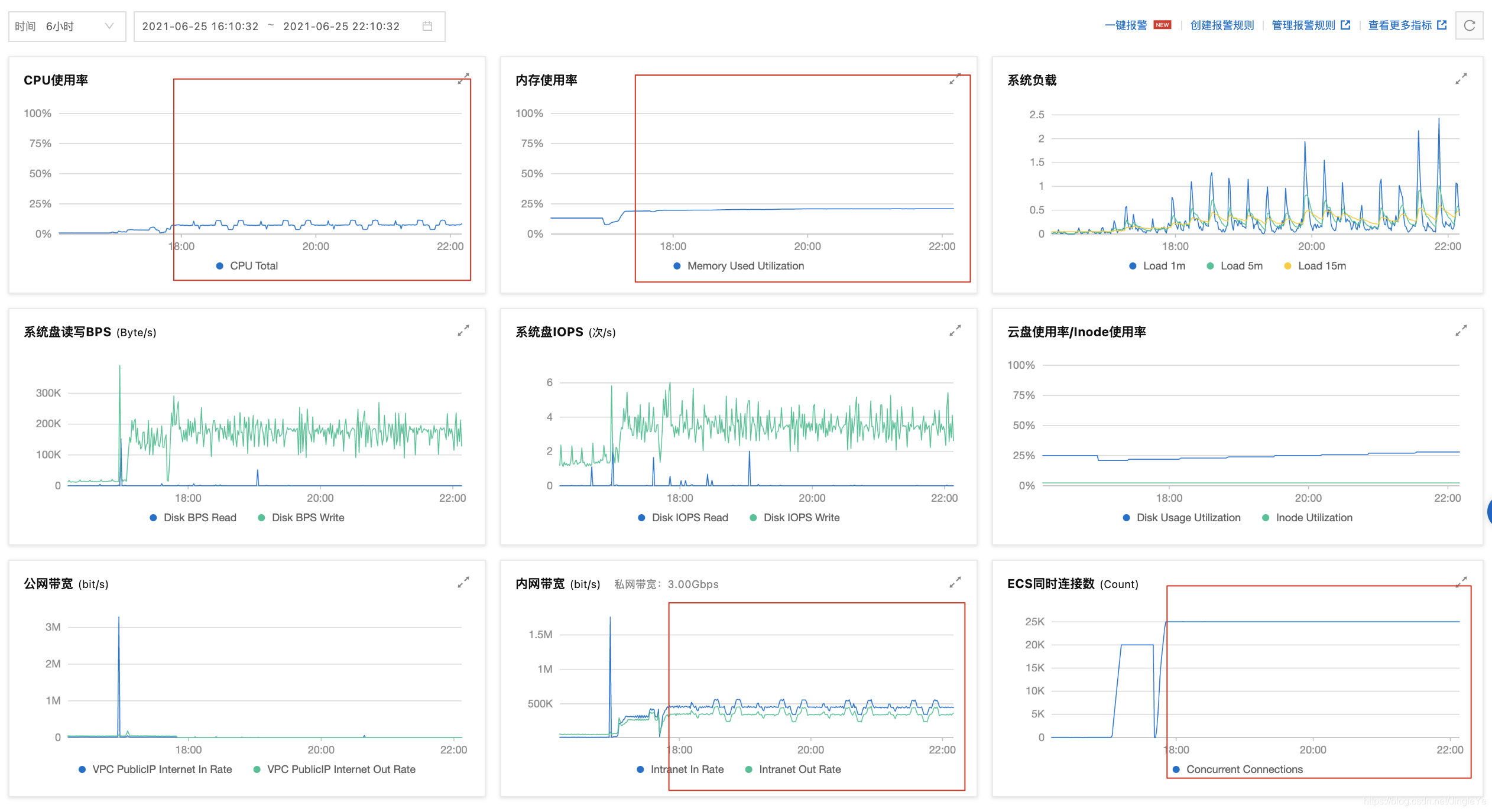
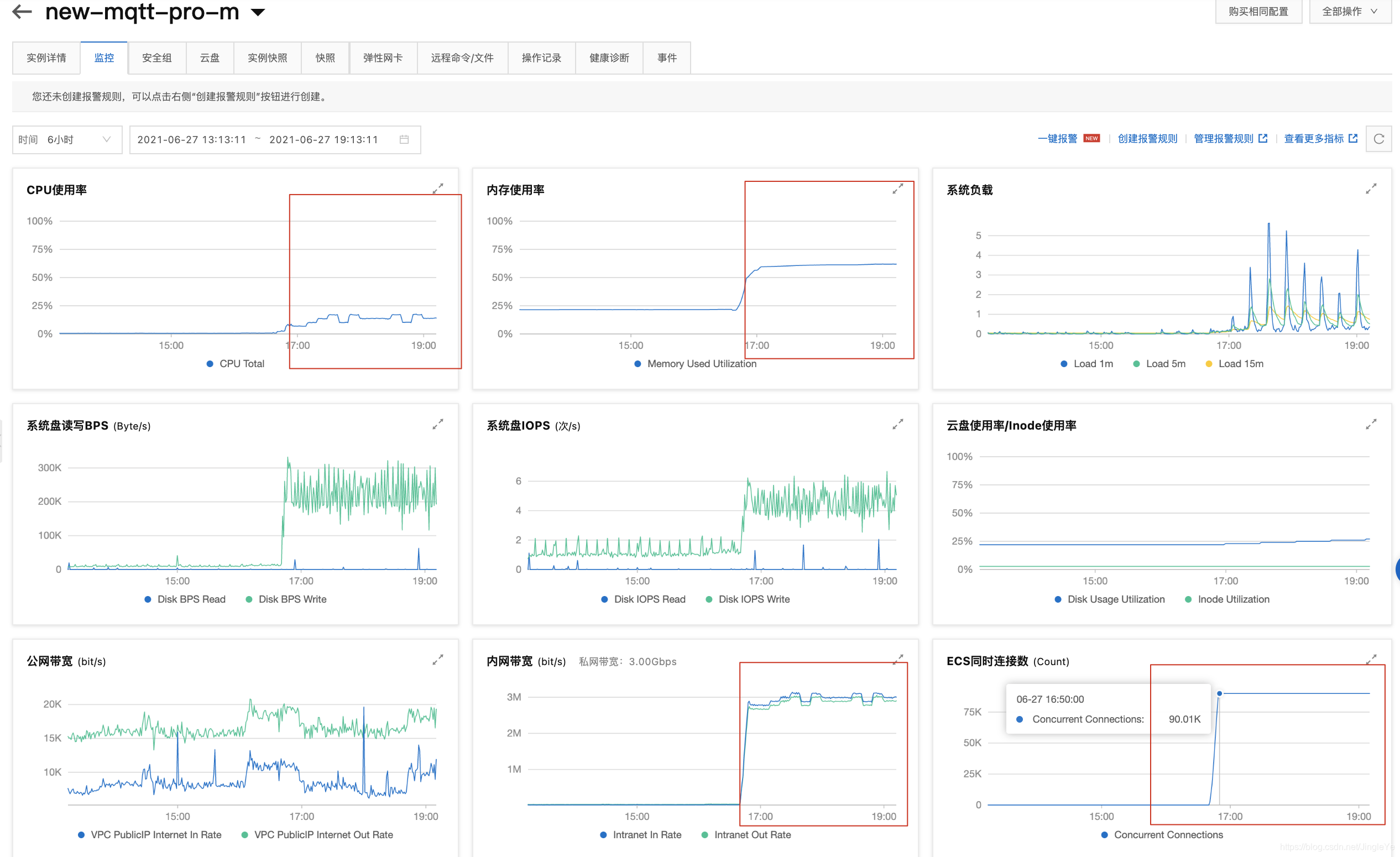
跑了4个小时的截图,smqtt服务A如下:
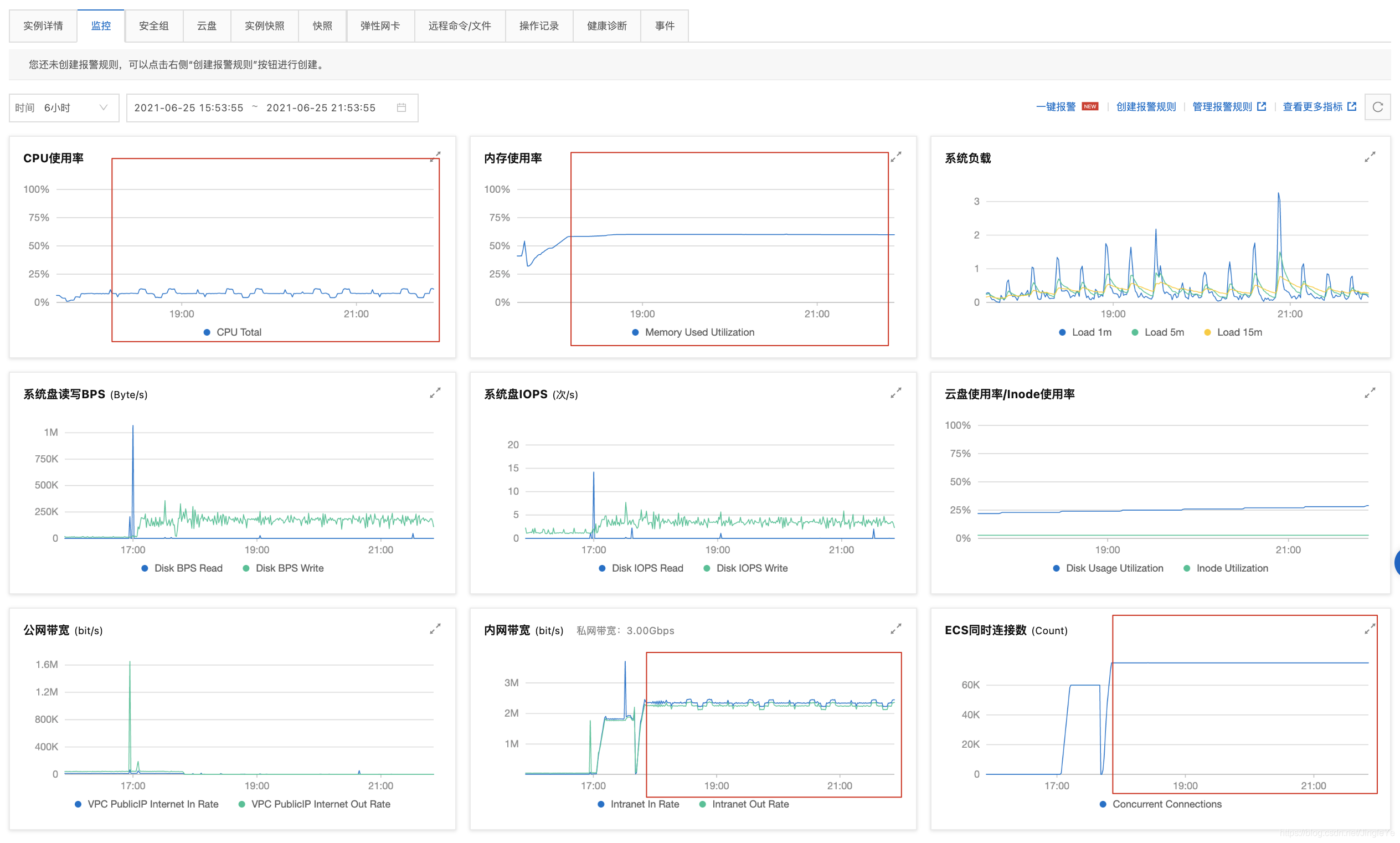
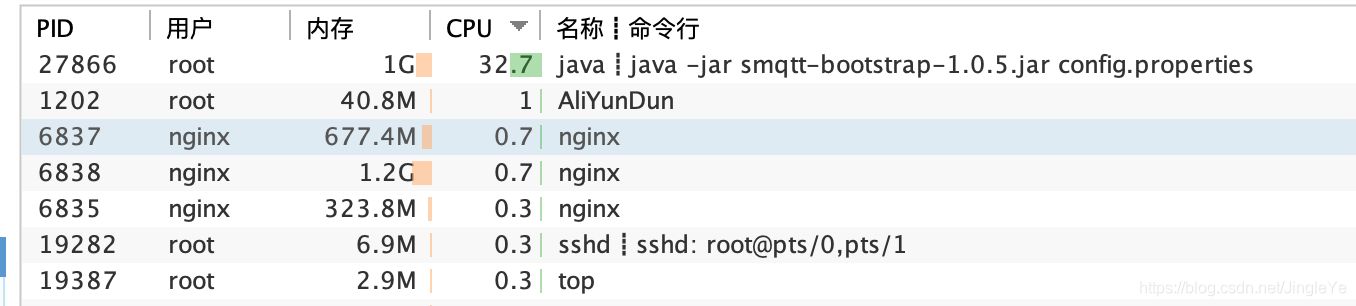
分析:
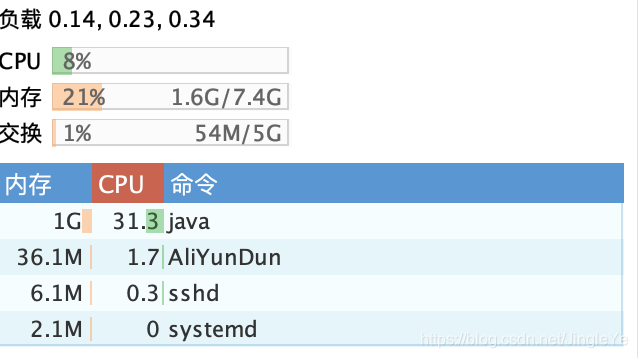
1、可以看到服务A,连接数达到75k,为什么会这么高呢?因为首先nginx接收了5万的连接,然后分流weight都为1(所以辅的要设置高一些)即这台服务器还连接着分流给服务B的2.5万,总的就是7.5万,而服务B连接只有2.5万; 2、内存占用了 4.4G,nginx占了2G左右,smqtt占了1G; 3、带宽这里2.2M/s,说明8M不够了,主要是所有的进出都走这里了,等到了这个承载量,起码要16M。
我们再看服务B,如图
 分析:
分析:
1、服务B入我们上面所说,2.5万连接; 2、带宽比较低,不超过450kb/s,主要是它少了nginx的大量承载,其实这里无所谓,因为是内网带宽。服务A不一样,是要接受外网客户端流量,而服务B只接受服务A那台服务器Nginx的分流。
集群2-优化分流比为主辅1:2,启用qos1
第1台,Nginx+服务A,weight=1
第2台,服务B,weight=2
这里设置1:2,是因为,nginx基本不怎么耗cpu,主要还是连接比不要差距太大,或者可以考虑,单独部署nginx来分流,就不用这么麻烦。另外,也可以考虑去买阿里的负载均衡。
另外,这里Nginx需要配置连接的最大数量,worker_rlimit_nofile与worker_connections,我都设置了60万,自行百度了。
设备端模拟:
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=40000 -receivers=40000 -publishers=10000 -cid=cccccccccccc -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=1 -keepalive=120s -s=44 -I=1200000 -clear=true >run.log 2>&1 &
APP端模拟:
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=10000 -receivers=10000 -publishers=10000 -cid=app-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-aaaaaaaaa -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=1 -keepalive=120s -s=44 -I=1800000 -clear=true >run.log 2>&1 &
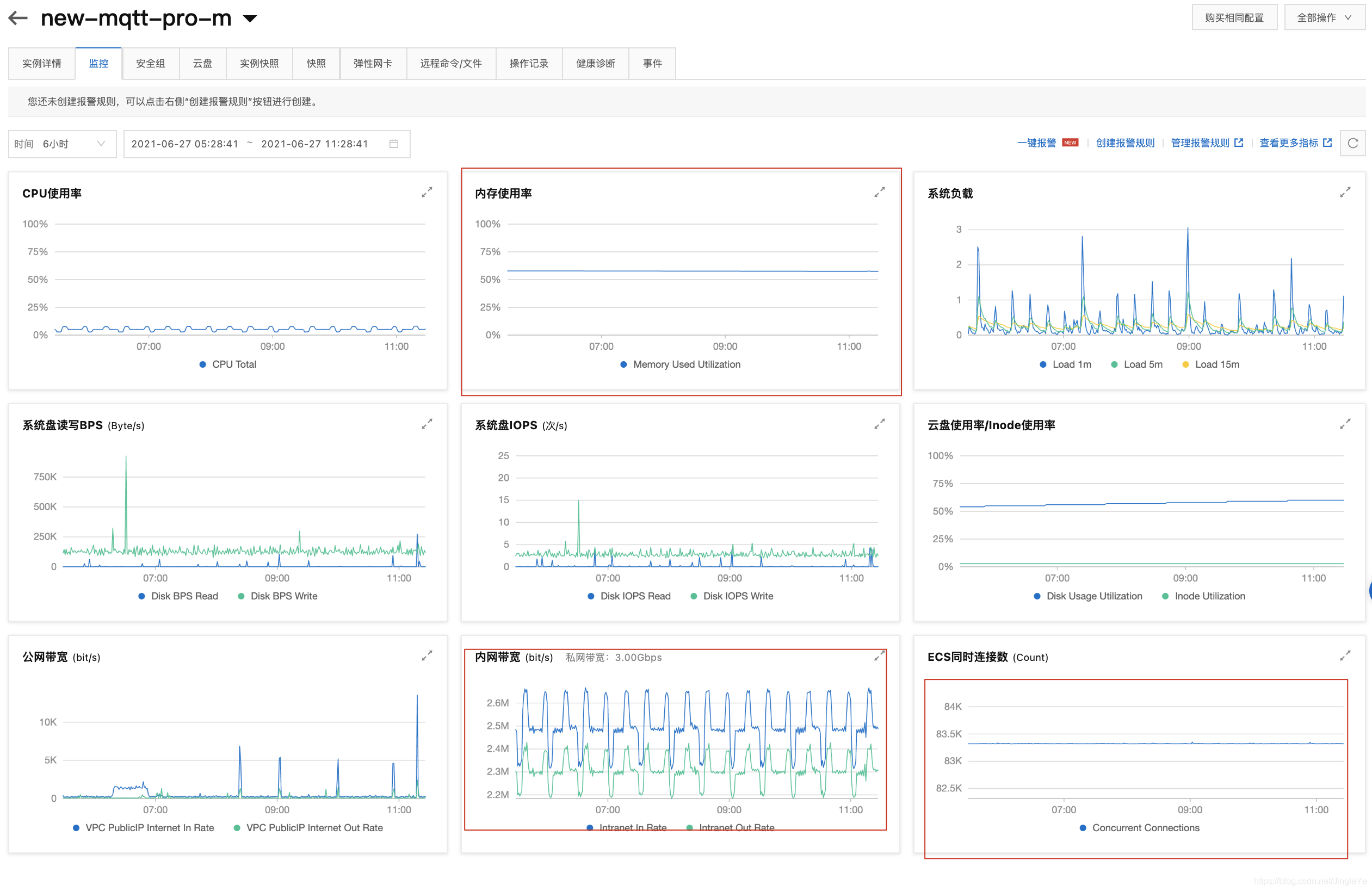
开始测试,我们可以预见,服务A连接数为5万+3.4万(分流服务B)=8.4万,服务B连接数为3.4万。我们一会再看下结果。
服务A

 分析:
分析:
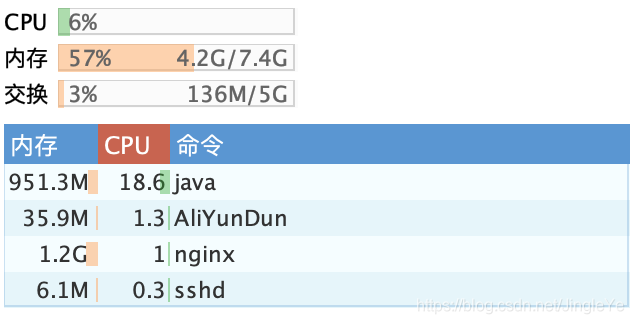
1 连接数8.33万,内存950M,cpu20%左右,符合我们的预估,但是连接数比第一种情况更高,感觉weight还是1:1好。 2 内存和带宽感消费比较多,等设备数增长后,可以提升主服务器带宽。
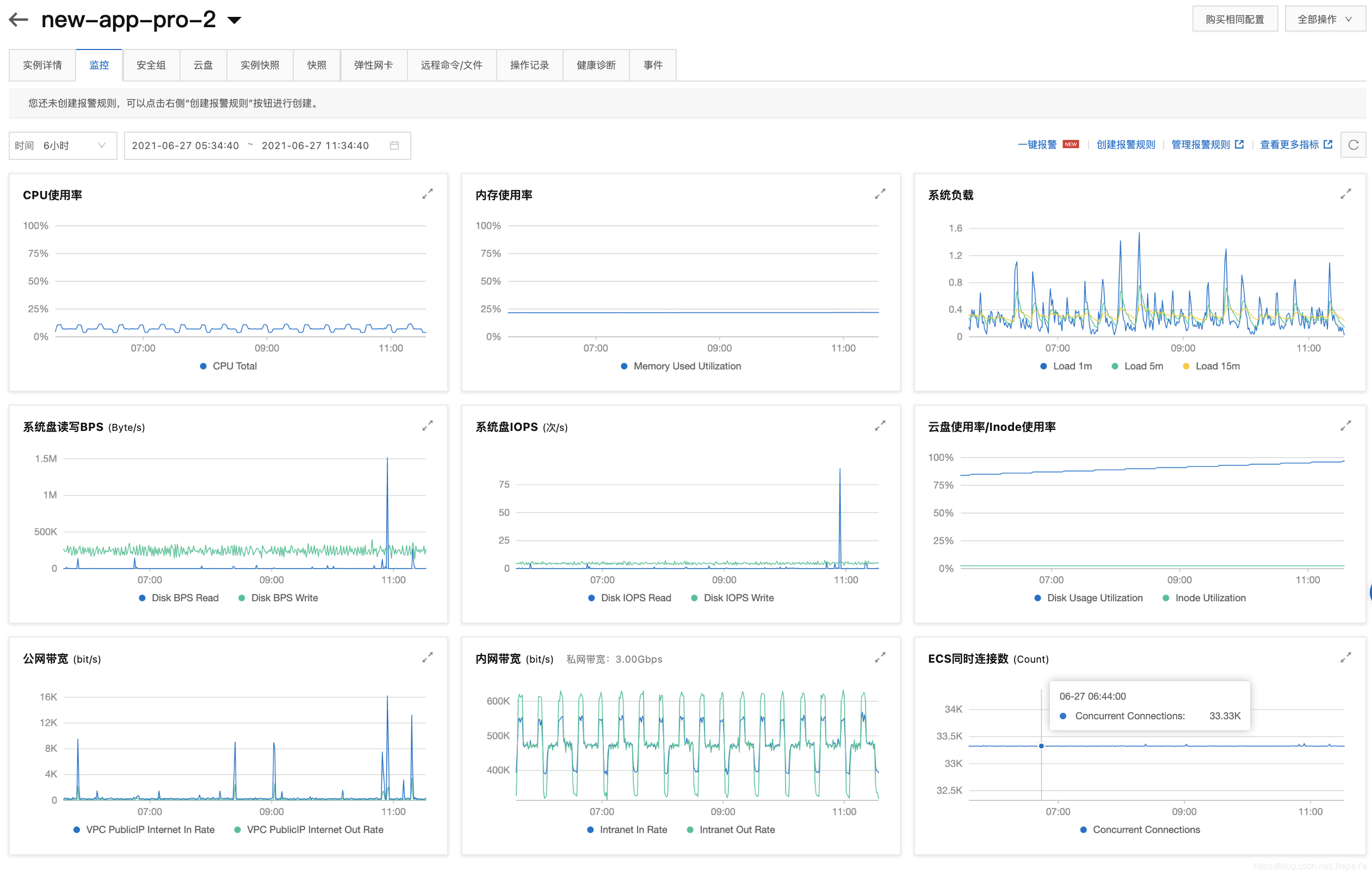
服务B
 分析:
分析:
1 连接数3.3万多,符合预期,但是cpu增多了,在45%左右(消息多的时候,也不都是在这里,还是消息不均,30%-45%,但总的是升高了),主服务器才20%,我觉得在内存都ok的情况下,cpu应该为主。故第一种方案weight为1:1还是更好一些。
集群3-提高压力,高峰期支撑50%用户/小时
当前来说cpu400%,可以说是还有非常大的余地,以下测试就当是验证一下是否真有这么多余地。
这种情况我们再分析一下:
1 我们还是假定有40000个设备,同一时间,设备通常只有1个人在操作,可以不考虑授权的用户,同样假定40000个用户。 2 这样子设备端就有40000个链接,订阅40000个topic,设备被操作一次,会反馈2条消息(运行中,成功),20000个发布者,针对高峰期App端25000条/小时,这里应该是50000条/小时(833条/分钟,14条/秒) 3 而APP高峰期假设1小时有
50%的用户,就是20000个链接。 4 那App就是20000个链接,订阅20000个topic(设备的topic),20000个发布者,部分用户可能操作多次,所以消息可能有多,假设25%用户重复操作,那总是就有25000条/小时,每秒7条左右。
综合:高峰期总链接数是,6万个,topic:4万个,消息是75000条/小时(1250条/每分钟,21条/秒)
环境相同,weight改1:1,使用qos0,因为我们业务是qos0,各端情况如下:
-
设备端模拟:4万链接,4万订阅者,4万topic,2万发布者,50000条/小时===>50000/20000=2.5条/小时,每个发布者2.5条/小时(算3条,就是20分钟一条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=40000 -receivers=40000 -publishers=20000 -cid=cccccccccccc -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1200000 -clear=true >run.log 2>&1 &
-
APP端模拟:2万链接,2万订阅,2万topic,2万发布者,25000条/小时===>25000/20000=1.25条每小时。每个发布者1.25条/小时(算2条,30分钟1条消息),每条消息44字节
nohup ./cp7_bench_group_all -url=tcp://smqtt:smqtt@172.18.x.x:1883 -workers=20000 -receivers=20000 -publishers=20000 -cid=app-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-aaaaaaaaa -topic=aaaaaaaaaaaaaaaaaaaaaaaaaaa -qos=0 -keepalive=120s -s=44 -I=1800000 -clear=true >run.log 2>&1 &
开始测试,跑2个多小时后。
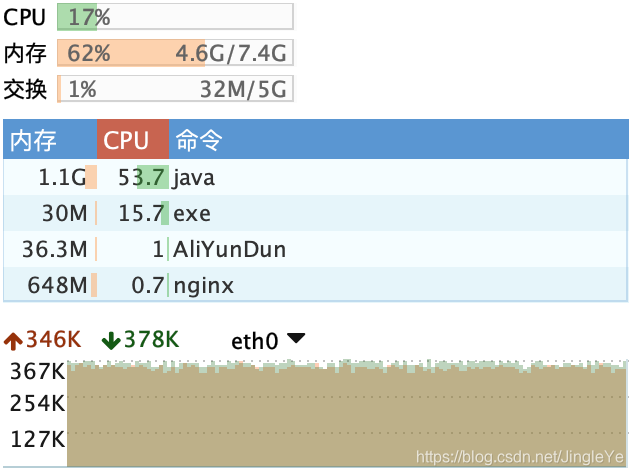
服务A截图:

分析:
1 服务A总内存4.6G相比之前4.4G没增加多少。 2 cpu为50%左右变化,相比之前32%,压力有增加了一些。 3 带宽达到2.9M/s,相比2.2M/s增加了不少,主要消息变多了。 4 总连接数据达到9万,因为接收6万还有分流服务B的3万。
服务B截图:

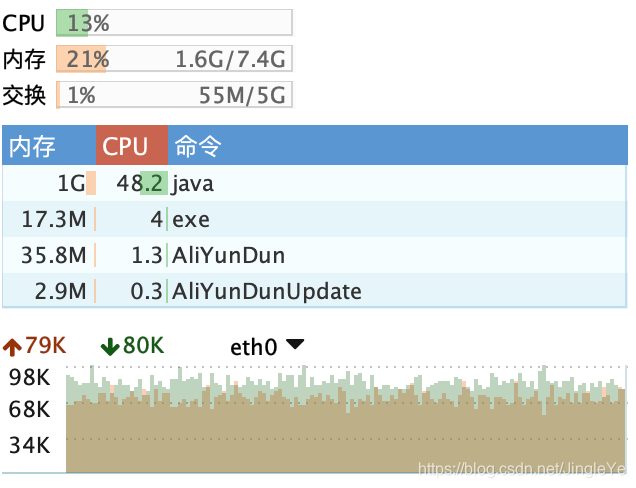
分析:
1 一样cpu达到了50%左右,压力稍微增大。 2 内存1G跟之前持平。
综合来说,cpu稍微压力增加了一些,带宽增加比较多,内存还好。另外,大概咱们估计下,这里2台都占50%来算,我们cpu4核,当cpu达到400%不考虑带宽的话,另外内存又变化不大,可以支撑48万连接,再打个折扣,40万应该可以!